Ceph CSI no Kubernetes
Usando CSI para montar volumes RBD e sistemas de arquivo cephfs

Aqui vai o relato fresquinho da experiência de um dos meus trabalhos mais recentes: o deploy de plugins CSI para o provisionamento automático de filesystems CephFS e volumes RBD.
Uma nota infeliz: o cluster Ceph foi instalado e é mantido por outras pessoas, e eu não tenho qualquer tipo de acesso. Então o relato vai ser incompleto, faltando os procedimentos do lado “de lá”. Se você está esperando aqui ideias para apoiar a instalação e configuração de clusters Ceph ou uso de soluções como o Rook, este não é o texto para você. O foco aqui está no deploy do CSI.
Vou ver se consigo um esboço de documentação combinada com eles e atualizar o texto no futuro!
Armazenamento no Kubernetes: para quê?
O mundo Kubernetes adora coisas stateless e microsserviços; tudo seria muito mais fácil para todos se não precisássemos nos preocupar com ter que guardar dados. Olha só que ideal: o Pod sobe, um sistema de arquivos é instanciado do zero com a aplicação, ele morre, tudo é descartado e todo mundo fica feliz.
Mas nem tudo (na verdade, praticamente nada) é da forma que gostaríamos. Precisamos resolver o problema das coisas stateful em um mundo pensado stateless.
Felizmente, temos aqui ao lado um cluster Ceph cheio de Terabytes livres pronto para resolver o problema de armazenamento. Quais são as opçõpes disponíveis? Bem, temos:
- Objetos (S3);
- RBD;
- CephFS;
Armazenamento de objetos (i.e., “S3”)
A primeira sugestão para este problema é: usa armazenamento de objetos estilo S3, ora!
É verdade, podemos usar esse recurso. Inclusive podemos, com algum grau de trabalho, usar o Ceph para criar uma interface S3-like. E funciona bem! A melhor parte: nenhuma modificação é feita nos sistemas de arquivo do container, sendo a opção ideal que demanda o mínimo do cluster Kubernetes em si. Todas as operações serão conduzidas pela aplicação diretamente contra a API pública do Ceph responsável pelo armazenamento de objetos.
Mas obviamente: se o trabalho não está do lado das operações, está do lado dos desenvolvedores. A aplicação precisa ser codificada para usar objetos.
Mas como você pode imaginar, armazenamento de objetos é um conceito novíssimo na computação, tipo, tem apenas umas poucas décadas. S3 surgiu apenas em 2006, tipo, praticamente ontem, a tecnologia sequer chegou à maioridade civil. Ainda não deu tempo de adaptar todo tipo de aplicação para este tipo de armazenamento. Talvez com a computação quântica chegar a gente consiga migrar tudo para S3 e ao mesmo tempo se ver livre do Cobol (/sarcasm)
Enfim, precisamos de alternativas ao armazenamento de objetos.
(Cicatrizes de batalha: Armazenamento de objetos no Ceph funciona, mas não sem alguma dor de cabeça: algumas coisas precisam de adaptação; por exemplo, até outro dia, o Spark Operator tinha dificuldades em ler objetos de S3 sem gerar um trabalhão gigantesco para customizar a imagem com as bibliotecas do Hadoop mais novo, mas isso não é tão relevante assim para o momento, apenas cuidado com os detalhes e a versão das libs que você vai usar!).
Armazenamento de bloco (block storage)
Precisamos de uma estratégia para instanciar dispositivos de bloco para servir como discos dos nossos Pods. O caso de uso mais simples é criar um disco dedicado para servir de volume de dados dedicado para um único Pod (embora você possa ser mais arrojado aqui).
Para isso, temos o Ceph Block Device, conhecido como RBD, que vai atuar em uma correspondência direta com serviços de nuvem como AWS EBS ou os Azure VHD page blobs (ainda não superei esse nome).
Sistema de arquivos de rede
Além dos blocos, uma outra solicitação comum por sistemas de arquivo de rede distribuídos ao estilo NFS (que inclusive é uma opção no Kubernetes a um custo de complexidade relativamente baixo).
Podemos usar o Ceph Filesystem ou CephFS para esta finalidade.
Qual o jeito “certo” de usar Ceph no Kubernetes?
Das três opções que temos, o armazenamento de objetos depende única e exclusivamente da aplicação, e por isso é uma favorita de 10 em cada 10 administradores de infraestrutura.
As outras duas demandam algum conhecimento e configuração tanto do lado Kubernetes quanto do lado Ceph.
Levando em consideração que começamos nossa história com Kubernetes na versão 1.4, a integração com Cephfs e RBD originalmente implantada faz uso do código nativo do Kubernetes (também chamado de “in-tree”) para a montagem dos volumes, e segue assim até hoje. Entretanto, para um novo projeto, decidi fazer uso da Container Storage Interface (CSI) para fazer as novas integrações.
A CSI graduou para stable com o Kubernetes 1.13, e a ideia é a mesma dos demais CxI: desacoplar o código do Kubernetes dos diferentes providers de coisas. Não há razão para não usá-la exceto:
- preguiça;
- incompatibilidade;
- instabilidade;
Obviamente somos profissionais da #ResistênciaOPS, então preguiça não é problema; vamos avaliar o resto!
Ceph CSI
Algumas informações relevantes estão disponíveis no site do projeto Ceph CSI. A primeira delas é que saiu uma nova release no dia em que eu comecei a escrever essa documentação, então minha implantação já está defasada (nota: já atualizei)!
A segunda é a ‘support matrix’ que apresenta as funcionalidades e o estado delas, bem como as versões compatíveis.
A primeira informação relevante a ser extraída é que você só pode usar o Ceph CSI se seu cluster Ceph for ao menos 14.0.0 (Nautilus); isso foi uma barreira para minhas iniciativas até pouco tempo atras.
Reproduzindo a tabela encontrada em 09/12/2020:
| Plugin | Features | Feature Status | CSI Driver Version | CSI Spec Version | Ceph Cluster Version | Kubernetes Version |
|---|---|---|---|---|---|---|
| RBD | Dynamically provision, de-provision Block mode RWO volume | GA | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.14.0 |
| Dynamically provision, de-provision Block mode RWX volume | GA | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.14.0 | |
| Dynamically provision, de-provision File mode RWO volume | GA | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.14.0 | |
| Provision File Mode ROX volume from snapshot | Alpha | >= v3.0.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.17.0 | |
| Provision File Mode ROX volume from another volume | Alpha | >= v3.0.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.16.0 | |
| Provision Block Mode ROX volume from snapshot | Alpha | >= v3.0.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.17.0 | |
| Provision Block Mode ROX volume from another volume | Alpha | >= v3.0.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.16.0 | |
| Creating and deleting snapshot | Alpha | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.17.0 | |
| Provision volume from snapshot | Alpha | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.17.0 | |
| Provision volume from another volume | Alpha | >= v1.0.0 | >= v1.0.0 | Nautilus (>=14.0.0) | >= v1.16.0 | |
| Expand volume | Beta | >= v2.0.0 | >= v1.1.0 | Nautilus (>=14.0.0) | >= v1.15.0 | |
| Metrics Support | Beta | >= v1.2.0 | >= v1.1.0 | Nautilus (>=14.0.0) | >= v1.15.0 | |
| Topology Aware Provisioning Support | Alpha | >= v2.1.0 | >= v1.1.0 | Nautilus (>=14.0.0) | >= v1.14.0 | |
| CephFS | Dynamically provision, de-provision File mode RWO volume | Beta | >= v1.1.0 | >= v1.0.0 | Nautilus (>=14.2.2) | >= v1.14.0 |
| Dynamically provision, de-provision File mode RWX volume | Beta | >= v1.1.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.14.0 | |
| Dynamically provision, de-provision File mode ROX volume | Alpha | >= v3.0.0 | >= v1.0.0 | Nautilus (>=v14.2.2) | >= v1.14.0 | |
| Creating and deleting snapshot | Alpha | >= v3.1.0 | >= v1.0.0 | Octopus (>=v15.2.3) | >= v1.17.0 | |
| Provision volume from snapshot | Alpha | >= v3.1.0 | >= v1.0.0 | Octopus (>=v15.2.3) | >= v1.17.0 | |
| Provision volume from another volume | Alpha | >= v3.1.0 | >= v1.0.0 | Octopus (>=v15.2.3) | >= v1.16.0 | |
| Expand volume | Beta | >= v2.0.0 | >= v1.1.0 | Nautilus (>=v14.2.2) | >= v1.15.0 | |
| Metrics | Beta | >= v1.2.0 | >= v1.1.0 | Nautilus (>=v14.2.2) | >= v1.15.0 |
Tirando o fato de que o provisionamento dinâmico de CephFS se encontra em estágio Beta, não há nenhum grande empecilho à implementação.
Helm charts
Nenhum procedimento de instalação é listado de imediato, mas tanto o plugin CSI do rbd quanto do cephfs contam com Helm charts disponíveis para instalação!
Qual a primeira coisa que devemos fazer com Helm charts alheios? Baixar e fuçar:
# # Rede isolada :(
# source proxy-me-up.sh
# helm repo add ceph-csi https://ceph.github.io/csi-charts
# helm repo update
...
...Successfully got an update from the "ceph-csi" chart repository
...
# helm pull ceph-csi/ceph-csi-rbd
# helm pull ceph-csi/ceph-csi-cephfs
# # Nunca esquecer de desconfigurar as variáveis de proxy para não entrar em pânico quando der kubectl e receber um timeout.
# unset ${!HTTP*} ${!http*}
Mas voltando ao chart: uma coisa que já me deixa triste éo fato de que não há uma maneira de você especificar um Docker Registry que faça ‘override’ global para todas as imagens - aparentemente estou acostumado demais com os fantásticos Helm charts da Bitnami.
E aqui vai uma lembrança nada a ver com o assunto Ceph CSI: em 20/11/2020, o Docker Hub ativou rate limit para usuários anônimos; portanto deixar o seu cluster baixar imagens diretamente de registries públicos, mesmo para teste, não é mais uma opção.
A primeira coisa a fazer é levantar quais as imagens usadas pelos Charts e quais os parâmetros que vou precisar customizar para usar meu Registry privado.
# # Eu prefiro isso a dar helm show values
# for i in ceph*.tgz ; do tar xvf $i ; done
# fgrep -A1 repository ceph-csi-cephfs/values.yaml ceph-csi-rbd/values.yaml
ceph-csi-cephfs/values.yaml: repository: k8s.gcr.io/sig-storage/csi-node-driver-registrar
ceph-csi-cephfs/values.yaml- tag: v2.0.1
--
ceph-csi-cephfs/values.yaml: repository: quay.io/cephcsi/cephcsi
ceph-csi-cephfs/values.yaml- tag: v3.2.0
--
ceph-csi-cephfs/values.yaml: repository: k8s.gcr.io/sig-storage/csi-provisioner
ceph-csi-cephfs/values.yaml- tag: v2.0.4
--
ceph-csi-cephfs/values.yaml: repository: k8s.gcr.io/sig-storage/csi-attacher
ceph-csi-cephfs/values.yaml- tag: v3.0.2
--
ceph-csi-cephfs/values.yaml: repository: k8s.gcr.io/sig-storage/csi-resizer
ceph-csi-cephfs/values.yaml- tag: v1.0.1
--
ceph-csi-cephfs/values.yaml: repository: k8s.gcr.io/sig-storage/csi-snapshotter
ceph-csi-cephfs/values.yaml- tag: v3.0.2
--
ceph-csi-rbd/values.yaml: repository: k8s.gcr.io/sig-storage/csi-node-driver-registrar
ceph-csi-rbd/values.yaml- tag: v2.0.1
--
ceph-csi-rbd/values.yaml: repository: quay.io/cephcsi/cephcsi
ceph-csi-rbd/values.yaml- tag: v3.2.0
--
ceph-csi-rbd/values.yaml: repository: k8s.gcr.io/sig-storage/csi-provisioner
ceph-csi-rbd/values.yaml- tag: v2.0.4
--
ceph-csi-rbd/values.yaml: repository: k8s.gcr.io/sig-storage/csi-attacher
ceph-csi-rbd/values.yaml- tag: v3.0.2
--
ceph-csi-rbd/values.yaml: repository: k8s.gcr.io/sig-storage/csi-resizer
ceph-csi-rbd/values.yaml- tag: v1.0.1
--
ceph-csi-rbd/values.yaml: repository: k8s.gcr.io/sig-storage/csi-snapshotter
ceph-csi-rbd/values.yaml- tag: v3.0.2
Daqui podemos observar que:
- A imagem do plugin CSI é a mesma para ambos;
Será que dá para consolidar ambos em um único pod de instalação? Isso pode ser útil para evitar ter que consumir metade do Pod Limit dos nodes com pods de ‘overhead’. Mas este não é meu problema no momento, vou optar pela comodidade do Helm chart pronto.
- Os plugins precisam de diversos outros componentes CSI para funcionarem.
E com um bônus: agora eles aparentemente alinharam as versões dos 5 componentes extras entre os 2 charts.
Cicatrizes de batalha: se você, como eu, gosta de acompanhar os projetos individualmente e usar sempre a versão mais recente, é bastante provavel que você não possa fazer isso aqui. A evolução dos componentes CSI caminha por uma trilha diferente dos drivers CSI dos fornecedores. Você necessariamente precisa usar as versões ‘homologadas’ por estes ou vai se dar mal.
Apenas para referência, a versão na qual fiz todos os testes (3.1.2, de apenas 20 dias atrás) usavam as seguintes versões, bem mais antigas:
# # jsonpath
k get pods -o jsonpath='{range .items[*].spec.containers[*]}{.image}{"\n"}{end}' | sort | uniq | cut -f3 -d'/' | sort | uniq
cephcsi:v3.1.2
csi-attacher:v2.1.1
csi-node-driver-registrar:v1.3.0
csi-provisioner:v1.6.0
csi-resizer:v0.5.0
csi-snapshotter:v2.1.0
csi-snapshotter:v2.1.1
Onde tem a informação do que é compatível com o que?
Bem, além da tabela que copiei acima indicando as versões do CSI demandadas, você pode olhar… no Helm chart. Ou nos yamls de exemplo. Não parece haver uma tabela de referência em outro lugar no site. Vou entrar no Slack do projeto e averiguar - não havendo, quem sabe contribuir?
Análise dos componentes do CSI
Eu gosto de entender os templates dos Helm charts para implantações; se o festival de go-templates te deixar pouco confortável, possivelmente eles replicam o que está nestes exemplos:
A partir da análise dos manifests, dá para entender a dinâmica dos componentes. Ambos usam uma organização de componentes semelhante:
- Deployment de Provisioner;
- Daemonset de nodePlugin.
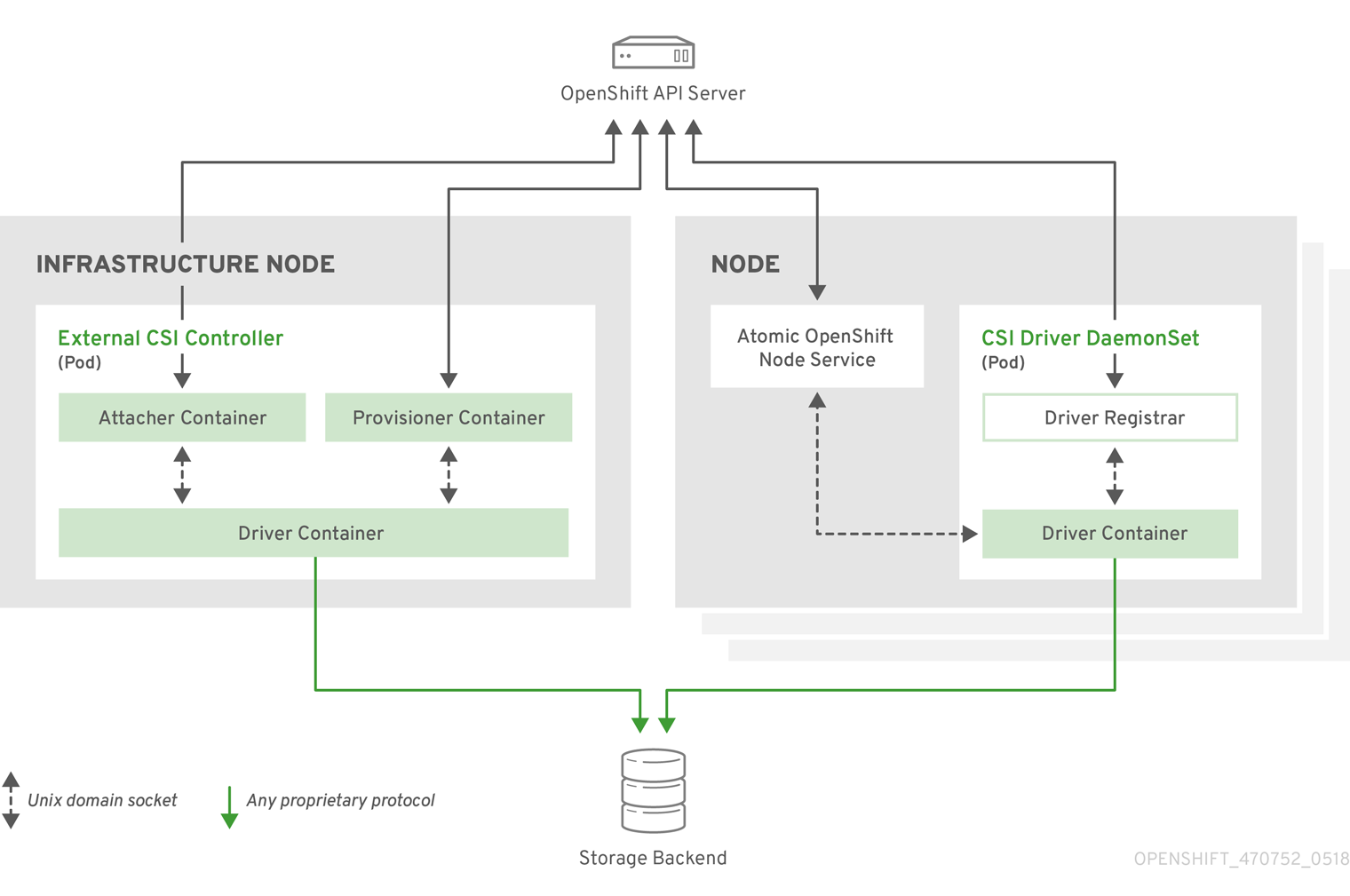
Eu poderia copiar as ASCII Arts do projeto CSI que são bem legais, mas acho que a Red Hat fez um desenho que ilustra bem a ideia dos componentes descritos nas próximas sessões:
Provisioners
Os provisioners são os ‘controller’ propriamente ditos, que irão monitorar a API do Kubernetes e executar as principais ações relacionadas aos volumes do ponto de vista do cluster;
São executados como Deployments a título de redundância, em que apenas um de seus Pods está ativo em um dado momento. Contém diversos containers; os comuns a ambos os drivers são:
Os provisioners são Pods com múltiplos containers, e precisam “carregar” os seguintes módulos para implementar a tradução de chamadas Kubernetes via CSI:
- csi-provisioner: o external provisioner do Kubernetes CSI; o controller responsável pela monitoração dos PersistentVolumeClaims criados e dispara as funções de criar e remover os volumes dos plugins CSI do Ceph.
- csi-attacher: o external-attacher fica com as chamadas de API CSI responsáveis pelo uso dos volumes por nodes;
- csi-resizer: o external-resizer, que intuitivamente implementa as chamadas para redimensionamento de PVCs;
- csi-snapshotter: o external-snapshotter, também intuitivamente responsável pela monitoração de CRDs de Snapshot e gerenciar seu ciclo de vida. Este plugin virou GA apenas no Kubernetes 1.20, mas o Ceph CSI indica o uso deste recurso como Alpha, então vale a precaução.
Além destes componentes externos ao projeto, os CSI também usam:
- liveness-prometheus: o próprio plugin cephcsi executando em modo ‘–type=liveness’, dedicado a garantir o estado do Pod e a exportar métricas;
Por fim, uma nova versão do plugin cephcsi é executada das seguintes formas, dependendo do tipo de componente usado.
Para o CephFS:
- csi-cephfsplugin: um único container, executado em modo ‘–type=cephfs’, responsável pela comunicação com os containers que executam os drivers nos nós;
Para o RBD:
- csi-rbdplugin: um container em modo ‘–type=rbd’.
- csi-rbdplugin-controller: um container em modo ‘–type=controller’.
NodePlugins
Os nodePlugins são executados em todas as máquinas de workload, que são aquelas que irão efetivamente mapear os volumes para pods.
São executados como Daemonsets para subir em todas as máquinas do cluster. Recebem diretamente a tradução das chamadas CSI realizadas ao driver ‘provisioner’ e implementam as operações de montagem dos sistemas de arquivos e dispositivos de blocos.
Os Pods de ambos executam três containers:
- driver-registrar: o node-driver-registrar registra o driver CSI no Kubelet daquele host;
- liveness-prometheus: o próprio plugin cephcsi executando em modo ‘–type=liveness’, de maneira semelhante ao executado nos provisioners;
O terceiro container é o driver propriamente dito:
- csi-rbdplugin ou csi-cephfsplugin: o driver cephcsi, executando no modo apropriado, e responsável pelas operações de mapeamento dos dispositivos e montagem dos sistemas de arquivo cephfs.
Considerações de segurança adicionais: este Pod, pela sua natureza, demanda privilégios especiais; executa com as diretivas ‘hostPID=true’, ‘hostNetwork=true’ além de mapear diversos volumes.
Observações relevantes
Entender devidamente a função de cada componente demanda leitura do documento de design dos CSI.
Importante: como o driver CSI do Ceph e os demais componentes têm seu desenvolvimento dissociado um do outro, eles evoluem em ritmos diferentes. Consequentemente, versões mais novas de algun dos 4 componentes ‘CSI’ do lado do Kubernetes não necessariamente são compatívels com as implementações dos plugins.
Onde tem a informação do que é compatível com o que? Em lugar nenhum. É necessário olhar os helm charts dos releases ou os manifests de exemplo disponibilizados pelo projeto.
Instalação
Pré-requisitos
Como falei lá no começo, não tenho acesso ao Ceph (apenas temporariamente mwahaha), então precisei interfacear com os administradores do cluster Ceph para que me repassassem as informações necessárias.
Para implantar os CSI, precisamos de dois tipos de informações:
-
Parâmetros de configuração:
- Cluster_ID: esta informação é crítica e corresponde ao identificador único do Ceph para o cluster Kubernetes. Aviso de antemão que depurar configurações divergentes de cluster_id entre cluster ceph e kubernetes por incrível que pareça não é tão trivial.
- Endereçamento IP do cluster: tanto dos monitores quando dos demais componentes. A rede é importante para possível liberação de regra em firewall, mas para o processo de instalação mesmo, a única coisa que precisamos configurar é os endereços IP de todos os Monitors do cluster.
- Portas: Idealmente, na configuração, devemos evitar especificar as portas e deixar o cliente usar da maneira que der. Por que isso? Os Ceph Monitors usam duas portas por padrão: 3300 e 6789. Cada porta atende a uma versão diferente do protocolo msgr, sendo a porta 3300 a mais nova. Dependendo do tipo de uso, uma versão será usada, ou a outra.
- subvolumeGroup: parâmetro relevante para o CephFS. O valor default é “csi"; algo diferente demandará configuração.
-
Credenciais com as permissões corretas.
Os parâmetros (1.) você irá passar para o Helm no ato da instalação. Você não precisa das credenciais para a instalação dos plugins, então é possível dissociar estas duas etapas.
As credenciais (2.) devem ser configuradas no processo de criação das StorageClasses. Elas não são configuradas pelos Helm charts - eles instalam os plugins CSI apenas.
Como infelizmente meu cluster ainda não conta com acesso ao Git interno (um mês não é tempo suficiente para criação de regras de firewall) mas os meus prazos precisam ser cumpridos, eu não poderei usar GitOps para fazer o deploy dos CSI.
(Quando eu finalmente conseguir implantar o Fluxv2, eu prometo que vou descrever aqui).
Instalação do Ceph CSI RBD
É possível executar o helm install passando um arquivo de values, que é mais estético e prático. Eu prefiro chamar na linha de comando dezenas de –set como a tripa gigante abaixo. De brinde, segue a maneira não descrita pela documentação oficial para aplicar –set em Lists na linha de comando em Helm charts.
Para este comando, precisamos dos seguintes pré-requisitos:
- ID do cluster: torça para que não passem errado para você;
- IPs dos monitores.
Estas informações irão virar um campo ‘config.json’ em um Configmap chamado ceph-csi-config-rbd.
# export PRIVATE_REPO=hub.intra/resistenciaOPS
# helm install \
--namespace "csi" \
--create-namespace=true \
ceph-csi-rbd \
/srv/k8s-bootstrap/charts/ceph-csi-rbd \
--set configMapName=ceph-csi-config-rbd \
--set kmsConfigMapName=ceph-csi-rbd-encryption-kms-config \
--set csiConfig[0].clusterID=6969197-ddf7-418f-8f07-3e6744c6af80 \
--set csiConfig[0].monitors[0]=192.168.69.1 \
--set nodeplugin.registrar.image.repository=$PRIVATE_REPO/csi-node-driver-registrar \
--set nodeplugin.plugin.image.repository=$PRIVATE_REPO/cephcsi \
--set nodeplugin.nodeSelector.'node-role\.kubernetes\.io/worker'='' \
--set provisioner.provisioner.image.repository=$PRIVATE_REPO/csi-provisioner \
--set provisioner.attacher.image.repository=$PRIVATE_REPO/csi-attacher \
--set provisioner.resizer.image.repository=$PRIVATE_REPO/csi-resizer \
--set provisioner.snapshotter.image.repository=$PRIVATE_REPO/csi-snapshotter \
--set provisioner.nodeSelector.'node-role\.kubernetes\.io/master'='' \
--set provisioner.tolerations[0].key=node-role.kubernetes.io/master \
--set provisioner.tolerations[0].effect=NoSchedule \
--set provisioner.replicaCount=2
Os únicos comentários relevantres sobre o comando acima são:
- set configMapName=ceph-csi-config-rbd: as duas versões agora usam o mesmo nome de configmap. Tentar instalar as duas com o helm irá gerar conflito. As alternativas são: modificar o nome do configmap e torná-los independente de novo, ou configurar a diretiva ‘externallyManagedConfigmap’, que provavelmente é a melhor. Sou preguiçoso e fui com a primeira.
- set nodeplugin.nodeSelector: não tenho interesse de executar o plugin em todas as máquinas do Cluster, apenas naquelas que eu considero ‘workers’. Desta forma, não irão subir, por exemplo, 2 Pods para isso no Master.
- set provisioner.nodeSelector/provisioner.tolerations: já o provisioner é o contrário: eu quero que ele rode apenas nos nós de Control Plane.
- set provisioner.replicaCount=2 porque só tenho dois masters.
Por que eu quero que ele rode nos nós de Control plane?
# k exec -it -c csi-rbdplugin ceph-csi-rbd-provisioner-6dff8cf8f4-7jxft -- whoami
root
Eu poderia rodar um comando ‘helm status’ para mostrar para vocês o resultado da execução, mas o Helm 3 quebrou o helm status, e a issue em aberto há um ano e meio não me deixa muito otimista quanto à resolução.
Segue um resultado com o que ele pode vir a instalar, dependendo dos parâmetros:
# helm get manifest ceph-csi-rbd | yq -r '"\(.kind):\(.metadata.name)"'
ServiceAccount:ceph-csi-rbd-nodeplugin
ServiceAccount:ceph-csi-rbd-provisioner
ConfigMap:ceph-csi-config-rbd
ConfigMap:ceph-csi-encryption-kms-config
ClusterRole:ceph-csi-rbd-provisioner
ClusterRole:ceph-csi-rbd-provisioner-rules
ClusterRoleBinding:ceph-csi-rbd-provisioner
Role:ceph-csi-rbd-provisioner
RoleBinding:ceph-csi-rbd-provisioner
Service:ceph-csi-rbd-nodeplugin-http-metrics
Service:ceph-csi-rbd-provisioner-http-metrics
DaemonSet:ceph-csi-rbd-nodeplugin
Deployment:ceph-csi-rbd-provisioner
Se quiser mais detalhes, pode pedir assim:
# for i in $( helm get manifest ceph-csi-rbd | yq -r '"\(.kind):\(.metadata.name)"' ) ; do kubectl get ${i/:/ } -o yaml ; read ; done
Instalação do Ceph CSI Cephfs
Muito semelhante ao anterior:
# export PRIVATE_REPO=hub.intra/resistenciaOPS
# helm install \
--namespace "csi" \
--create-namespace=true \
ceph-csi-cephfs \
/srv/k8s-bootstrap/charts/ceph-csi-cephfs \
--set configMapName=ceph-csi-config-cephfs \
--set csiConfig[0].clusterID=6969d032-c77e-4c55-a560-d559c2f41058 \
--set csiConfig[0].monitors[0]=192.168.69.1 \
--set nodeplugin.registrar.image.repository=$PRIVATE_REPO/csi-node-driver-registrar \
--set nodeplugin.plugin.image.repository=$PRIVATE_REPO/cephcsi \
--set nodeplugin.nodeSelector.'node-role\.kubernetes\.io/worker'='' \
--set provisioner.provisioner.image.repository=$PRIVATE_REPO/csi-provisioner \
--set provisioner.attacher.image.repository=$PRIVATE_REPO/csi-attacher \
--set provisioner.resizer.image.repository=$PRIVATE_REPO/csi-resizer \
--set provisioner.snapshotter.image.repository=$PRIVATE_REPO/csi-snapshotter \
--set provisioner.nodeSelector.'node-role\.kubernetes\.io/master'='' \
--set provisioner.tolerations[0].key=node-role.kubernetes.io/master \
--set provisioner.tolerations[0].effect=NoSchedule \
--set provisioner.replicaCount=2
Basicamente as mesmas considerações da instalação anterior valem para cá.
Ele cria basicamente as mesmas coisas:
# helm get manifest ceph-csi-cephfs | yq -r '"\(.kind):\(.metadata.name)"'
ServiceAccount:ceph-csi-cephfs-nodeplugin
ServiceAccount:ceph-csi-cephfs-provisioner
ConfigMap:ceph-csi-config-cephfs
ClusterRole:ceph-csi-cephfs-provisioner
ClusterRole:ceph-csi-cephfs-provisioner-rules
ClusterRoleBinding:ceph-csi-cephfs-provisioner
Role:ceph-csi-cephfs-provisioner
RoleBinding:ceph-csi-cephfs-provisioner
Service:ceph-csi-cephfs-nodeplugin-http-metrics
Service:ceph-csi-cephfs-provisioner-http-metrics
DaemonSet:ceph-csi-cephfs-nodeplugin
Deployment:ceph-csi-cephfs-provisioner
Criação das StorageClasses
Vou usar as pouco inspiradas StorageClasses abaixo:
- rbd: aqui há um campo importante que não há em outro lugar: o pool RBD. A única imageFeature suportada é ‘layering’.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ceph-rbd
allowVolumeExpansion: true
mountOptions:
- discard
parameters:
clusterID: 6975d032-c77e-4c55-a560-d559c2f41058
csi.storage.k8s.io/controller-expand-secret-name: ceph-rbd
csi.storage.k8s.io/controller-expand-secret-namespace: csi
csi.storage.k8s.io/fstype: xfs
csi.storage.k8s.io/node-stage-secret-name: ceph-rbd
csi.storage.k8s.io/node-stage-secret-namespace: csi
csi.storage.k8s.io/provisioner-secret-name: ceph-rbd
csi.storage.k8s.io/provisioner-secret-namespace: csi
imageFeatures: layering
pool: kubernetes
provisioner: rbd.csi.ceph.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
- cephfs:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ceph-cephfs
allowVolumeExpansion: true
mountOptions:
- debug
parameters:
clusterID: 6969d032-c77e-4c55-a560-d559c2f41058
csi.storage.k8s.io/controller-expand-secret-name: ceph-cephfs
csi.storage.k8s.io/controller-expand-secret-namespace: csi
csi.storage.k8s.io/node-stage-secret-name: ceph-cephfs
csi.storage.k8s.io/node-stage-secret-namespace: csi
csi.storage.k8s.io/provisioner-secret-name: ceph-cephfs
csi.storage.k8s.io/provisioner-secret-namespace: csi
fsName: cephfs
mounter: kernel
provisioner: cephfs.csi.ceph.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
Aqui indicamos as secrets que serão usadas para provisionamento, no caso ceph-cephfs e ceph-rbd.
Criação da secrets
Para RBD, é necessário especificar uma userID e uma userKey:
# k create secret generic ceph-rbd \
--type='kubernetes.io/rbd' \
--from-literal=userID='usuario' \
--from-literal=userKey='chave'
Já o CephFS precisa de dois conjuntos de credenciais distintas: além de uma userID com sua chave, é necessário usar uma chave de admin:
# k create secret generic ceph-cephfs \
--type='kubernetes.io/cephfs' \
--from-literal=userID='usuario' \
--from-literal=userKey='chave' \
--from-literal=adminID='usuario' \
--from-literal=adminKey='chave'
Por que isso? A diferença é descrita por estes dois crípticos comentários:
# Required for statically provisioned volumes
userID: <plaintext ID>
userKey: <Ceph auth key corresponding to ID above>
# Required for dynamically provisioned volumes
adminID: <plaintext ID>
adminKey: <Ceph auth key corresponding to ID above>
A melhor explicação para a diferença está aqui, o que traz certo alívio em ver que não é nada fantástico: ‘statically provisioned’ são volumes que você criou na mão, e não o provisioner.
Testes
Neste primeiro momento, não queremos testar funcionalidades avançadas. Os objetivos de testes são simples:
- Se o componente provisioner de cada plugin CSI está conseguindo provisionar adequadamente o PV para o PVC solicitado;
- Se o componente que executa em cada nó está conseguindo montar os volumes ou sistemas de arquivo.
Para cada teste, vamos subir um tipo diferente de objeto Kubernetes:
- Para testar o cephfs, vamos subir um deployment com pod anti affinity para que cada um suba em um nó diferente;
- Para testar o rbd, vamos subir um statefulset (com o mesmo anti affinity) que provisionará volumes por meio de diretivas volumeClaimTemplate.
Como temos 4 nós, o número de réplicas em cada um deles será 4.
Deployment de teste de CephFS
Aqui, nada de muito especial exceto a diretiva de anti-affinity usando a topologyKey que determina que um Pod sob este Deployment não subirá em um nó que já tenha um Pod deste deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: cephfs-testfs
name: cephfs-test
namespace: csi
spec:
replicas: 4
selector:
matchLabels:
app: cephfs-testfs
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: cephfs-testfs
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- cephfs-testfs
topologyKey: kubernetes.io/hostname
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
volumeMounts:
- mountPath: /var/lib/www
name: mypvc
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: pvc-cephfs
Antes de executar o Deployment acima, será necessário criar o PVC:
Aqui, o PVC não será criado automaticamente, você deve fazer isso.
# cat pvc-cephfs.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-cephfs
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: ceph-cephfs
O que acontece ao criar o PVC?
# k get pvc,pv
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/pvc-cephfs Bound pvc-f30393a6-42ee-4ffd-b3e5-784f1e940adc 1Gi RWX ceph-cephfs 2d11h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-f30393a6-42ee-4ffd-b3e5-784f1e940adc 1Gi RWX Delete Bound csi/pvc-cephfs ceph-cephfs 2d11h
Agora pode-se criar o deployment, que distribuirá os Pods adequadamente entre os nós, cada um montando o mesmo PVC oferecendo leitura e escrita concorrente:
# k get pods -l app=cephfs-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cephfs-test-1006230814-6winp 1/1 Running 0 24h 192.168.22.164 worker1.intra <none> <none>
cephfs-test-1006230814-fmgu3 1/1 Running 0 24h 192.168.19.42 worker2.intra <none> <none>
cephfs-test-1006230814-6ekbw 1/1 Running 0 24h 192.168.8.146 worker3.intra <none> <none>
cephfs-test-1006230814-fz9sd 1/1 Running 0 24h 192.168.20.24 worker3.intra <none> <none>
Statefulset de teste para RBD
Para quem não conhece, um statefulset é um Deployment diferente, que cria pods com nomes pré-definidos em uma ordem pré definida.
A ideia é garantir uma identidade própria e uma “unicabilidade” aos Pods (tentei transcrever a definição da melhor forma possível, foi isso que consegui, desculpem!).
A relevância de ser ou não Statefulset para este teste é menor; o que é importante mesmo é o fato de que existe um campo volumeClaimTemplate para pod que garante que o Kubernetes auto-instancie os PVCs necessários para o teste, tornando esta abordagem perfeita para o sysadmin preguiçoso!
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ceph-rbd-test
spec:
selector:
matchLabels:
app: ceph-rbd-test
serviceName: "nginx"
replicas: 4
template:
metadata:
labels:
app: ceph-rbd-test
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- ceph-rbd-test
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ceph-rbd"
resources:
requests:
storage: 1Gi
O que acontece ao criar o statefulset?
# k get pods -l app=ceph-rbd-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ceph-rbd-test-0 1/1 Running 0 24h 192.168.22.167 worker1.intra <none> <none>
ceph-rbd-test-1 1/1 Running 0 24h 192.168.19.41 worker2.intra <none> <none>
ceph-rbd-test-2 1/1 Running 0 24h 192.168.8.148 worker3.intra <none> <none>
ceph-rbd-test-3 1/1 Running 0 24h 192.168.20.23 worker3.intra <none> <none>
Os PVCs são criados automaticamente, assim como os PVs:
# k get pvc,pv
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/www-ceph-rbd-test-0 Bound pvc-4f1ca9bf-2c56-4ce4-8a6c-5bca290fd058 1Gi RWO ceph-rbd 24h
persistentvolumeclaim/www-ceph-rbd-test-1 Bound pvc-0bd15bb4-e782-46ec-90ce-10a779c95451 1Gi RWO ceph-rbd 24h
persistentvolumeclaim/www-ceph-rbd-test-2 Bound pvc-9f92d4e4-25e8-4f7c-9eab-2fc16c38b759 1Gi RWO ceph-rbd 24h
persistentvolumeclaim/www-ceph-rbd-test-3 Bound pvc-26548c61-f6fd-424f-a6e2-272ff559bf41 1Gi RWO ceph-rbd 24h
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-0bd15bb4-e782-46ec-90ce-10a779c95451 1Gi RWO Delete Bound csi/www-ceph-rbd-test-1 ceph-rbd 24h
persistentvolume/pvc-26548c61-f6fd-424f-a6e2-272ff559bf41 1Gi RWO Delete Bound csi/www-ceph-rbd-test-3 ceph-rbd 24h
persistentvolume/pvc-4f1ca9bf-2c56-4ce4-8a6c-5bca290fd058 1Gi RWO Delete Bound csi/www-ceph-rbd-test-0 ceph-rbd 24h
persistentvolume/pvc-9f92d4e4-25e8-4f7c-9eab-2fc16c38b759 1Gi RWO Delete Bound csi/www-ceph-rbd-test-2 ceph-rbd 24h
persistentvolume/pvc-f30393a6-42ee-4ffd-b3e5-784f1e940adc 1Gi
Com a criação dinâmica dos PVCs, nem é necessário olhar os status dos Pods, pois todos os volumes foram criados.
Observação importante: PVCs instanciados por statefulsets não são deletados automaticamente se o statefulset for deletado. Lembrar disso é importante para evitar acúmulo de lixo no cluster Ceph por testes esquecidos.
Erros comuns
Praticamente todos os erros vêm de duas coisas:
- Falha na conectividade com o cluster Ceph: que, ironicamente, não são relatadas exatamente de maneira trivial, mas por mensagens genéricas como “rpc error: code = Unknown desc = operation timeout: context deadline exceeded”;
- Falha na configuração dos plugins CSI: de longe a mais comum.
A experiência que tive na última semana trabalhando para viabilizar esta implantação é que depurar a integração com o Ceph é um pesadelo. Não sei apontar de quem exatamente é a culpa, se das mensagens pouquíssimo claras do plugin ou se da nossa deficiência interna em obter logs relevantes dos componentes do Ceph.
Batemos em todo tipo de dificuldade:
- Erro de credencial;
- Cluster_id incorreto;
- Pool incorreto;
- Erro de permissão;
- Erro de protocolo (especificando a porta 3300, que era incompatível);
- Usuários com mesmo conjunto de permissão recebendo respostas diferentes para suas requisições (um falhava, o outro funcionava);
- Possível bug obscuro em que uma das máquinas simplesmente não montava o volume;
É importante sempre ‘limpar’ todo o ambiente entre cada testes (possivelmente a sujeira foi a causa do bug obscuro relatado acima).
Mas o processo de depuração foi basicamente auto tune, por meio de ‘guessing games’, dos parâmetros configurados.
Uma coisa importante é: não confie no provisionamento automático dos PVs para garantir que a implementação está operacional. O problema pode vir na forma da montagem dos volumes nas máquinas - lembrar que o CSI tem dois componentes, o ‘Provisioner’ que traduz as requisições CSI e o ‘NodePlugin’ que executa em cada nó.
Não foi a melhor das experiências, e pretendo voltar (quando tiver acesso ao Ceph) para averiguar uma maneira mais inteligente para fazer essa depuração.