Kubernetes on-premises - parte 3
Tráfego de entrada em clusters Kubernetes

Outros capítulos da série Kubernetes on-premises:
- Kubernetes on-prem - parte 1: Introdução.
- Kubernetes on-prem - parte 2: Redes em Kubernetes - CNI e Calico.
Clusters Kubernetes: modelo de tráfego auto-contido
Na parte 2 da série “Kubernetes on-premises”, abordei, de maneira bastante superficial, sobre o fato de que o Kubernetes gosta da ideia de abstrair certas implementações, como a execução de contêineres, provisionamento de volumes para armazenamento persistente e especialmente redes.
Para viabilizar as principais ideias do Kubernetes de provisionamento automático, self healing e alta disponibilidade de seus workloads, o Kubernetes faz uso de uma série de recursos que só são implementados dentro do próprio cluster, como o conceito de Services.
A simples comunicação de contêineres em um cluster Kubernetes com o ‘resto do mundo’ não é trivial. Na própria parte 2 listei uma série de considerações que você deve fazer a respeito antes de integrar um cluster Kubernetes com seu datacenter “tradicional” - e acredite, não cheguei nem perto de exaurir a discussão.
Mas o primeiro desafio real que o Kubernetes te impõe e que alguém com pouca experiência certamente não está preparado é: como fazer o resto do mundo se conectar aos meus sistemas dentro do cluster? Que opções temos?
Service do tipo ClusterIP
Para garantir a alta disponibilidade e recuperação rápida de falhas, tudo no Kubernetes gira em torno dos Services, em particular do tipo ClusterIP.
Eu poderia descrever o que são Services e como são implementados a partir do Kube-proxy e do CoreDNS, mas eu prefiro mostrar da seguinte forma:
- Eu tenho três Pods ‘nginx’, cada um executando em um servidor:
# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx1 1/1 Running 0 2m20s app=nginx
nginx2 1/1 Running 0 2m11s app=nginx
nginx3 1/1 Running 0 2m8s app=nginx
- Eu crio um Service associado ao label app=nginx, como visto na coluna SELECTOR. Ele recebe um IP de um range especial, cujo padrão é 10.96.0.0/12.
# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx ClusterIP 10.96.0.128 <none> 80/TCP 114s app=nginx
- Isso quer dizer que o Service está associado aos três Pods, como pode ser visto no objeto Endpoints:
# kubectl get endpoints
NAME ENDPOINTS AGE
nginx 192.168.18.136:80,192.168.19.8:80,192.168.22.135:80 2m58s
- A partir de um outro Pod ou de um Nó do cluster, você pode acessar os Pods nginx (que estão na Namespace teste) usando o nome DNS nginx.teste.svc.cluster.local. Você verá que as conexões são balanceadas entre os três:
# for i in {1..1000} ; do curl -s nginx.teste.svc.cluster.local. ; done | sort | uniq -c
334 Voce se conectou ao pod nginx1
333 Voce se conectou ao pod nginx2
333 Voce se conectou ao pod nginx3
Fantástico, não? O que é ainda melhor, se você deletar um dos pods, você não precisa se preocupar com nada: o Kubernetes irá atualizar os Endpoints do Service o que resultará no Pod excluído ser removido do balanceamento praticamente de forma instantânea:
# kubernetes delete pod nginx1
pod "nginx1" deleted
# kubernetes get endpoints
NAME ENDPOINTS AGE
nginx 192.168.19.8:80,192.168.22.135:80 19m
# for i in {1..1000} ; do curl -s nginx.teste.svc.cluster.local. ; done | sort | uniq -c
500 Voce se conectou ao pod nginx2
500 Voce se conectou ao pod nginx3
Esse exemplo é “estúpido” porque uso pods criados manualmente e foi feito apenas para entender o conceito. Mas imagine: se os Pods fossem mantidos por um ReplicaSet de um Deployment que fizessem uso de Liveliness e Readiness checks, é o conceito de Service que:
- Aguardam Pods recém criados estarem prontos para serem incluidos no balanceamento;
- Remove do balanceamento Pods que entram em estado NotReady;
- Viabilizam as RollingUpdates dos Deployments sem causar impacto aos usuários;
É o conceito de Service, associado aos Controllers que mantém o estado dos objetos do cluster Kubernetes que dão a esta tecnologia o ‘Wow factor’ de abstrair algo que todo mundo precisa e, no mundo real, é extremamente complexo de fazer.
Mas enfim, me empolguei com o exemplo, e acabei perdendo o foco. O que eu realmente queria falar é que, embora Services sejam o máximo, ele está visível apenas “dentro” cluster Kubernetes 1 e não te ajuda em nada para resolver o problema de fazer chegar comunicação externa aos seus Pods.
1 Isso é verdade do ponto de vista do Kubernetes ‘puro e simples’, existem maneiras de integrar tanto a resolução de nomes quanto a divulgação dos endereço IP dos ClusterIPs usando Calico, por exemplo. Quer saber mais sobre isso? Entre em contato comigo e me deixe saber!
Cicatrizes de batalha: prestou atenção no CIDR padrão usado pelos Services do tipo ClusterIP? Se, na sua empresa, você usar o range 10.96.x.y para outras coisas, você terá prolemas com o valor padrão, e acredite: mudar isso após a implantação vai ser uma das piores experiências da sua vida.
Service do tipo NodePort
Uma das maneiras encontradas para resolver o problema da comunicação do mundo externo com clusters Kubernetes foram os Services do tipo NodePort.
Este tipo de configuração literalmente escolhe uma porta de um range pré determinado (30000-32767) e a abre em todos os nós daquele cluster Kubernetes, que direcionará todas as comunicações aos Endpoints associados ao Service.
Se você achou feio e tosco, é porque é mesmo. É algo que é operacional e “dá para conviver”, mas é uma solução totalmente desprovida de elegância.
E se eu disser que é a única solução oferecida nativamente pelo Kubernetes para viabilizar o acesso externo?
Não acredita?
Service do tipo Loadbalancer
Está na ponta da língua das pessoas a resposta de que NodePort não é a única maneira, afinal também temos os Services do tipo Loadbalancer, certo? Então, gostaria de fazer um ‘quote’ da definição da documentação oficial:
On cloud providers which support external load balancers, setting the type field to LoadBalancer provisions a load balancer for your Service.
Ou seja, em cloud providers que suportem, você vai conseguir usar este recurso com facilidade. Fora delas, você está por sua própria conta; os services Loadbalancers não fazem absolutamente nada e o Kubernetes, por si só, não vai te ajudar a resolver este problema 2.
2 O projeto Metallb, iniciado três anos atrás, existe com o objetivo de preencher esse ‘gap’, mas não é uma solução oficial integrada ao Kubernetes, e é descrito pelo próprio projeto como Beta. Estando dissociado do Kubernetes, a evolução e maturidade de ambos os projetos estão completamente desacopladas.
Ingress
Havendo esgotado as possibilidades de Services para atender ao nosso problema, pelo menos ainda temos Ingress para servir ao menos o tráfego HTTP(S)? do nosso cluster nativamente, certo?
Errado! Não existe controller nativo no Kubernetes para Ingress! Novamente, da documentação oficial:
You must have an Ingress controller to satisfy an Ingress. Only creating an Ingress resource has no effect.
O único consolo é que, diferentemente dos Services, em que temos apenas uma única opção (Metallb), a oferta de Ingress Controllers para clusters Kubernetes é bem maior, inclusive com algumas opções pagas que oferecem suporte de fornecedores como Nginx, HAproxy e F5.
O fato de haver diversas opções funciona de maneira semelhante ao CNI: acaba atrapalhando mais que ajudando aqueles que estão começando agora no universo Kubernetes. Como escolher o que melhor vai atender às suas necessidades?
Há um agravante: a maior dificuldade de lidar com Ingress Controllers não é nem os softwares em si, e sim o fato de que o Ingress resource do Kubernetes é extremamente espartano em termos de parâmetros de configuração, ao se comparar com o que o ‘mercado’ demanda. E isso não é acidental:
This API has intentionally been kept simple and lightweight, but there has been a desire for greater configurability for more advanced use cases. Work is currently underway on a new highly configurable set of APIs that will provide an alternative to Ingress in the future. These APIs are being referred to as the new “Service APIs”. They are not intended to replace any existing APIs, but instead provide a more configurable alternative for complex use cases. For more information, check out the Service APIs repo on GitHub.
Isso quer dizer duas coisas:
- Em um futuro próximo, será necessário mudar tudo;
- Não existe um Ingress Controller igual ao outro.
Cada Ingress implementa um conjunto distinto de funcionalidades - e de uma forma diferente. Projetos que dependem de Ingress acabam lançando seus próprios Controllers (como o Istio Service Mesh ou o Kong Api Service). As configurações são tipicamente realizadas por meio de Annotations nos objetos Ingress ou por meio de CRDs. Basicamente cada Ingress Controller é uma história diferente, e será necessário uma quantidade não razoável de leitura e testes para determinar qual o mais apropriado para cada uso.
Outra coisa que é importante dissociar é o Ingress Controller (o programa que atuará monitorando o Kubernetes e buscando reconciliar as configurações com as mudanças) dos softwares que efetivamente fazem o “proxy reverso” recebendo as conexões e entregando aos Pods no seu cluster. Existem todo tipo de opção e topologias. A familiaridade prévia e experiências (positivas ou negativas) podem e devem guiar sua escolha. Se você tem ampla experiência com HAproxy, será muito mais fácil tentar identificar problemas, gargalos e oportunidades de ‘tuning’ se você optar por um Ingress Controller que faça uso do HAproxy que com algo completamente novo, ainda que mais ‘moderno’ como Traefik ou Envoy.
Esta planilha, oferecida pelo site Kubedex, contém uma comparação lado-a-lado de alguns dos principais Ingress Controllers; infelizmente não há uma marcação de quando foi a última atualização.
Este outro post traz uma breve descrição e é relativamente recente (07/2020).
Eu não vou me aprofundar em análises dos diversos Ingress Controllers existentes porque eu tenho experiência real com apenas dois. Vou contar um pouco da minha experiência com eles.
Nginx Ingress Controller
Antes de falar qualquer outra coisa, é importante deixar dois fatos muito importantes sobre o Nginx Ingress Controller:
- Embora esteja listado no Github como estando abaixo do projeto Kubernetes, o conjunto de pessoas envolvidas na manutenção e evolução do Ingress Controller é outro completamente diferente do projeto Kubernetes em si, o que faz com que o nível de maturidade do software, assim como o Metallb, seja outro completamente diferente.
- Este projeto não é o mesmo que oferece suporte oficial pela empresa Nginx. Este projeto usa a versão ‘community’ do Nginx; a versão mantida pela empresa (que foi comprada pela F5) usa a versão Plus e uma ‘codebase’ completamente diferente.
As duas considerações acima não significam que o projeto seja ruim, mas é importante ter essa noção antes de implantar o que provavelmente vai se tornar o ponto mais crítico da sua infraestrutura.
Por exemplo: o Nginx Community Edition não oferece a funcionalidade de reconfiguração dinâmica dos seus upstreams por meio de API; este código está disponível apenas na versão Plus.
Cada ‘reload’ de configuração demanda a substituição dos workers Nginx por dois novos, enquanto os processos antigos se mantém vivos por tempo suficiente para permitir que as conexões encerrem. Durante este tempo, o Nginx consumirá o dobro de memória RAM.
Dependendo da quantidade de ‘Reloads’ do seu cluster, o uso deste Ingress Controller pode se mostrar inviável.
O projeto entendeu que isso era uma séria limitação bem cedo, e implementou sua própria versão de um handler Lua que faz as vezes da API privada para mitigar esse problema.
Ainda assim, cenários como o abaixo podem ocorrer:
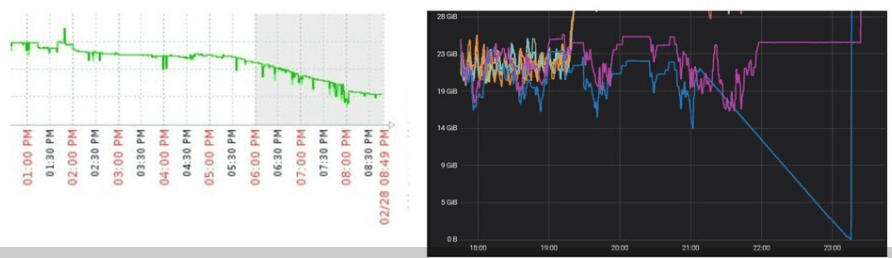
A imagem acima representa o consumo de memória RAM de servidores que executavam exclusivamente Nginx Ingress Controller em um cluster Kubernetes de produção. Os servidores contavam com 40GB de RAM. A versão já contava com o módulo Lua. É possível observar dois problemas:
- Não é possível mitigar todos os Reloads, mesmo com o módulo Lua;
- O código do Nginx é sólido e battle tested; o código do módulo Lua foi criado para este projeto, e está sujeito a problemas, como memory leaks que fazem o processo Nginx ocupar cada vez mais RAM com o tempo.
Esse memory leak da imagem acima já foi corrigido, e dificilmente a esmagadora maioria das pessoas passaria pela situação acima. Mas acredito que este relato seja suficiente para se entender que não é um simples componente deploy-and-forget para Kubernetes.
HAproxy Ingress Controller
Apenas para referência, eu implanto clusters Kubernetes antes mesmo do primeiro Ingress Controller existir.
E nessa época, bem antes da empresa HAproxy se interessar por Kubernetes, em uma época em que apenas o Nginx Ingress Controller sem módulo Lua existia, um herói resolveu fazer seu próprio Ingress Controller usando o HAproxy. O nome deste herói é Joao Morais e seu HAproxy Ingress Controller consegue a façanha de ainda hoje ser retornado acima do “oficial” no Google.
Como temos a sorte de ter Joao Morais trabalhando na nossa empresa, a escolha de qual Ingress Controller usar é meio que um ‘no-brainer’. Ele acompanha o uso diário de nossos servidores que atuam como Ingress, observando as limitações e identificando os problemas de escala e performance que vão surgindo. E acredite: nosso principal cluster Kubernetes oferecem problemas extremamente desafiadores que eu ouso dizer que não seriam atendidos por nenhum dos demais projetos.
O HAproxy Ingress Controller implementa um set de funcionalidades muito semelhante ao do Nginx Ingress Controller, que possivelmente é o mais usado atualmente. Por isso, é uma excelente segunda opção para testes, mesmo não sendo tão conhecido (embora ainda tenha mais estrelas no Github que o Ingress Controller HAproxy da própria HAproxy!).
Sendo ambos ‘Annotation based’, não é difícil manter ambos coexistindo no mesmo cluster. O único incômodo será manter dois conjuntos de annotations distintos para configurar os objetos Ingress.
A Annotation prefix padrão do Nginx Ingress Controller é nginx.ingress.kubernetes.io, enquanto no HAproxy Ingress Controller é ingress.kubernetes.io.
Como pontos positivos, posso ressaltar que:
- Se comporta extramemente bem em clusters com objetos completamente mal configurados;
- Consome quantidade irrisória de CPU, mesmo com contínua necessidade de reconciliação de configurações;
- Pode solicitar certificados Letsencrypt nativamente para seus backends sem softwares adicionais (salvo engano, foi o primeiro a implementar esta funcionalidade!);
Como pontos negativos, ficam que:
- Também é reload-oriented; situações que demandam ‘full-reload’ também impactam a memória, mas o tamanho do processo do haproxy tende a ser previsível, em contraste com o tamanho variável do Nginx devido ao módulo Lua;
- Menos mantenedores e menos colaboradores: como somos da #ResistênciaOPs, nós não colaboramos com qualquer tipo de código para o João, e se ele ganhar na Mega da Virada, pode ser que o projeto morra;
Conclusão
Infelizmente, esta é mais uma decisão difícil que um pretendente a administrador Kubernetes precisará tomar antes mesmo de colocar o primeiro sistema para rodar.
Se sua única preocupação é o direcionamento de tráfego HTTP/HTTPS, é uma questão de escolher qual o Ingress Controller que melhor atende ao seu caso.
Agora caso a conexão direta com os Pods sem intermediário seja necessária, você incorrerá em problemas. A única opção real é o projeto Metallb, e embora performe bem, tanto a documentação quanto sua implementação não são tão diretas ou triviais de serem aplicadas. Existe muito mais material hoje que em 2018 quando foi lançado, ainda assim vai demandar um esforço bem maior que o necessário para instalar todo o resto do cluster Kubernetes, por exemplo, para fazer uma implantação madura que vá além do ‘funcionou!’.
Alguns Ingress Controllers suportam ‘layer 4’ além de HTTP/HTTPS. Se isso for uma necessidade, essa questão já serve para ‘afunilar’ as opções. O Nginx, HAProxy de Joao e o Voyager eu sei que fazem de maneira relativamente simples. Salvo engano o Kong também suporta este recurso.
Pretende usar algum tipo de Service Mesh, provavelmente eles já resolvem o problema Ingress para você. Leia e torça que a solução te atenda totalmente; dificilmente você encontrará soluções intercambiáveis nesse assunto.
Agora se você está completamente desamparado de ideias e com preguiça de testar, o mais usado - e possivelmente com mais chances de encontrar e receber ajuda - é o Nginx Ingress Controller “oficial” do Kubernetes. O HAproxy de Joao Morais tende a depender única e exclusivamente dele para apoio, já que nós, que trabalhamos com ele, raramente damos qualquer tipo de ajuda em canal do Slack ou coisas do tipo por sermos funcionários públicos preguiçosos.
Ainda assim, recomendo testes regulares e acompanhamento de pelo menos umas duas ou três opções diferentes, se possível, para evitar que, algum dia, você seja contemplado com um bug fatal que ocorra apenas no seu ambiente e que impeça a atualização para novas versões do seu escolhido (como aconteceu conosco com o Nginx Ingress Controller por volta da versão 0.17).
Migrar de Ingress Controller a toque de caixa em um fim de semana não é uma experiência que eu recomende a ninguém!